この記事は、「AIリテラシー基礎講座」第3回です。
今回は、AIが自然な文章で間違える理由を、ハルシネーションや出典確認の視点から整理します。
シリーズ全体はこちら:【まとめ】AIリテラシーとは何か|生成AIを安全に使うための基礎講座まとめ

「突然ですが、AIを使っていて、こんな経験はありませんか?」
- もっともらしい答えなのに、よく見ると間違っている
- 存在しない本や論文を紹介された
- 古い制度や情報をもとに答えられた
- 数字や日付が少し違っていた
- 人名や地名を取り違えていた
- 出典を聞いたら、確認できない資料名が出てきた
- 質問の意図と少し違う方向に答えられた
AIは、とても便利です。
- 文章を要約する
- アイデアを出す
- 難しい話をやさしく説明する
- 構成を作る
- 質問に答える
- コードを書く
- 表を整理する
こうしたことができますが、AIは間違えます。
しかも、厄介なのは、間違った答えでも自然な文章で出てくることがある点です。
「明らかに変な答え」なら、私たちは気づきやすいです。
ですが、AIの間違いは、文体が整っていて、説明も自然で、専門用語も入っていることがあります。
そのため、正しそうに見えてしまいます。
Google Cloudは、AIハルシネーションを、AIモデルが生成する誤った、または誤解を招く結果と説明しています。
また、その原因として、不十分な学習データ、モデルの誤った仮定、学習データのバイアスなどを挙げています。(Google Cloud)
つまり、AIの間違いは、単なる「機械のミス」ではありません。
自然な文章を作る力が強いからこそ、間違いも自然に見えるのです。
今回は、「AIはなぜ間違えるのか」を見ていきます。
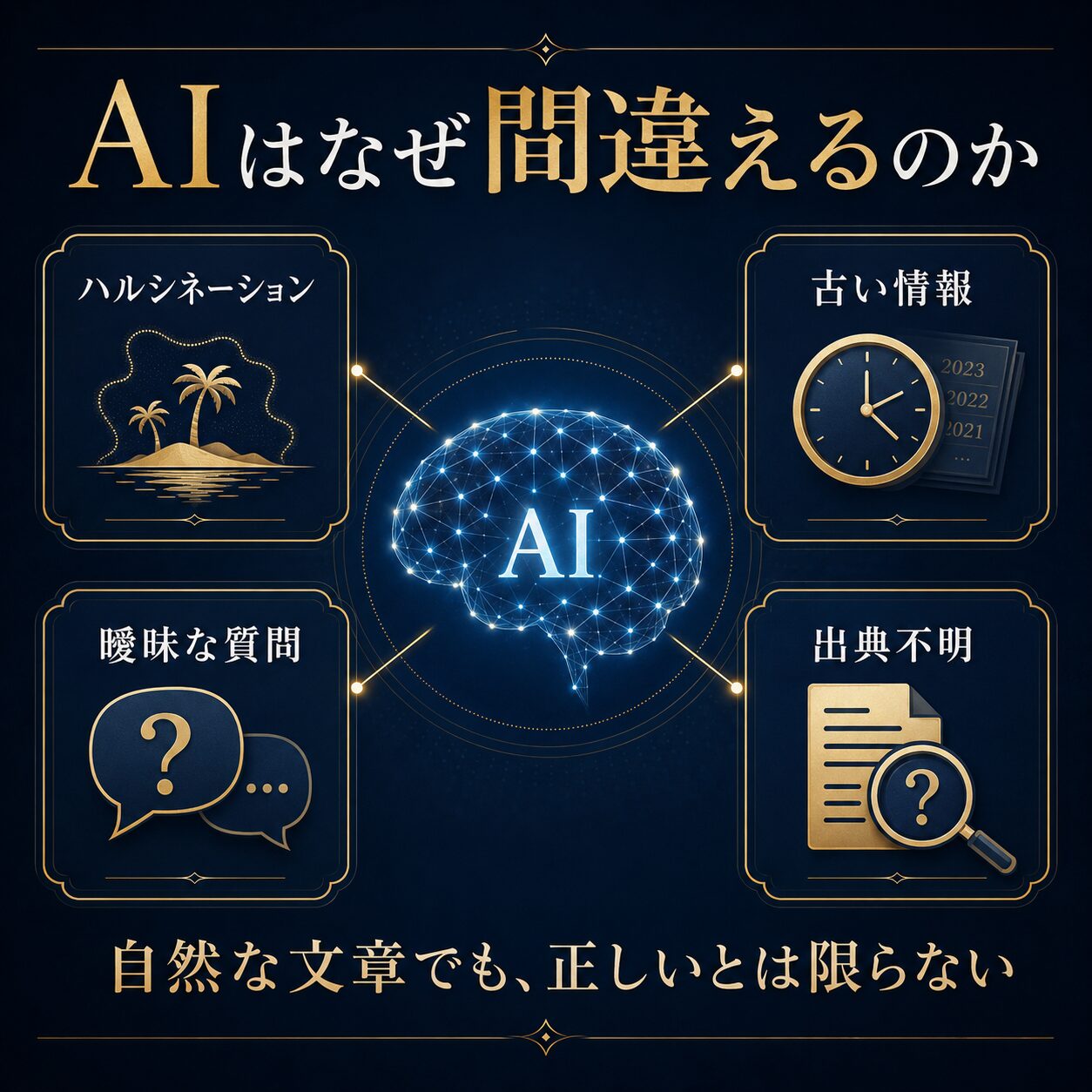
「ハルシネーションとは何か?」
「なぜ存在しない情報をそれらしく答えるのか?」
「なぜ古い情報や誤った情報が混ざるのか?」
「AIの間違いに、私たちはどう気づけばよいのか?」
こうした問いを、AIリテラシーの視点から整理していきます。
第1章 AIはなぜ「自然に間違える」のか?
AIの間違いがやっかいなのは、自然に見えることです。
人間が文章を読んだとき、次のような特徴があると「正しそう」と感じやすくなります。
- 文体が整っている
- 説明の流れが自然
- 専門用語が使われている
- 断定的に書かれている
- 数字や資料名が出てくる
- もっともらしい理由がついている
AIは、こうした文章を作るのが得意です。
前回見たように、生成AIは大量のデータから言葉のパターンを学び、文脈に合う自然な出力を作ります。
そのため、間違っていても、文章としては自然に見えることがあります。
文脈に合う答えを作る
↓
文章が自然になる
↓
正しそうに見える
↓
でも、事実として正しいとは限らない
ここで大切なのは、AIを「嘘つき」と見ることではありません。
AIは、人間のように悪意を持って嘘をついているわけではありません。
ただし、結果として、誤った情報をもっともらしく出すことがあります。
IBMは、AIハルシネーションの要因として、過学習、学習データの偏りや不正確さ、モデルの複雑さなどを挙げています。(IBM)
つまり、AIの間違いは、AIの仕組みとデータ、そして使い方の問題として見る必要があります。
第2章 ハルシネーションとは何か?

ハルシネーションとは、AIが事実ではない情報を、事実のように出力してしまう現象です。
日本語では、「幻覚」と訳されることもあります。
ただし、AIが本当に幻を見ているわけではありません。
AIが、存在しない情報や誤った情報を、それらしく生成してしまうことを指します。
たとえば、次のようなものです。
- 存在しない論文を紹介する
- 実在しない本のタイトルを出す
- 人物の経歴を間違える
- 事件の日付を間違える
- 法律や制度を古い情報で説明する
- 実在しない統計を出す
- 出典があるように見せる
- 引用文を作ってしまう
OpenAIは、ハルシネーションを、モデルが自信を持って真実ではない答えを生成する例と説明しています。
また、言語モデルでは、不確かなときに「わからない」と言うより、推測して答えることが評価されやすい訓練・評価の構造も問題になると説明しています。(OpenAI)
ここが重要です。
AIは、必ずしも「知らない」と答えるように作られているわけではありません。
むしろ、質問されると、文脈に合う答えを作ろうとします。
その結果、情報が不確かでも、もっともらしい答えを出すことがあります。
質問される
↓
文脈に合う答えを作ろうとする
↓
情報が不確かでも推測する
↓
自然な文章になる
↓
誤った答えが事実のように見える
ハルシネーションが危険なのは、AIの文章が不自然だからではありません。
むしろ、自然すぎるから危険なのです。
第3章 なぜ存在しない情報を作ってしまうのか?
AIが存在しない情報を作ってしまう理由は、AIが「正しい資料を探している」とは限らないからです。
生成AIは、質問に対して文脈に合う出力を作ります。
そのとき、資料名、著者名、日付、URLのようなものも、文章のパターンとして生成してしまうことがあります。
たとえば、あなたがAIにこう聞いたとします。
「AIと教育に関する有名な論文を3つ教えてください」
AIは、実在する論文を挙げることもあります。
一方で、ありそうなタイトル、ありそうな著者名、ありそうな学術誌名を組み合わせて、存在しない論文を出すことがあります。
なぜでしょうか?
AIにとっては、「論文紹介らしい形式」を作ることができるからです。
ここで大切なのは、形式と事実を分けることです。
AIは、もっともらしい形式を作るのが得意です。
ですが、その資料が実在するかどうかは、必ず確認する必要があります。
特に注意したいのは、次の情報です。
- 論文名
- 本のタイトル
- 統計データ
- 法律名
- 制度名
- 判例
- 人物の発言
- 引用文
- URL
- 年号
AIが「出典があります」と言っても、その出典が実在するとは限りません。
出典らしいものを出すことと、実在する出典を示すことは違うのです。
第4章 古い情報や誤った情報が混ざる理由
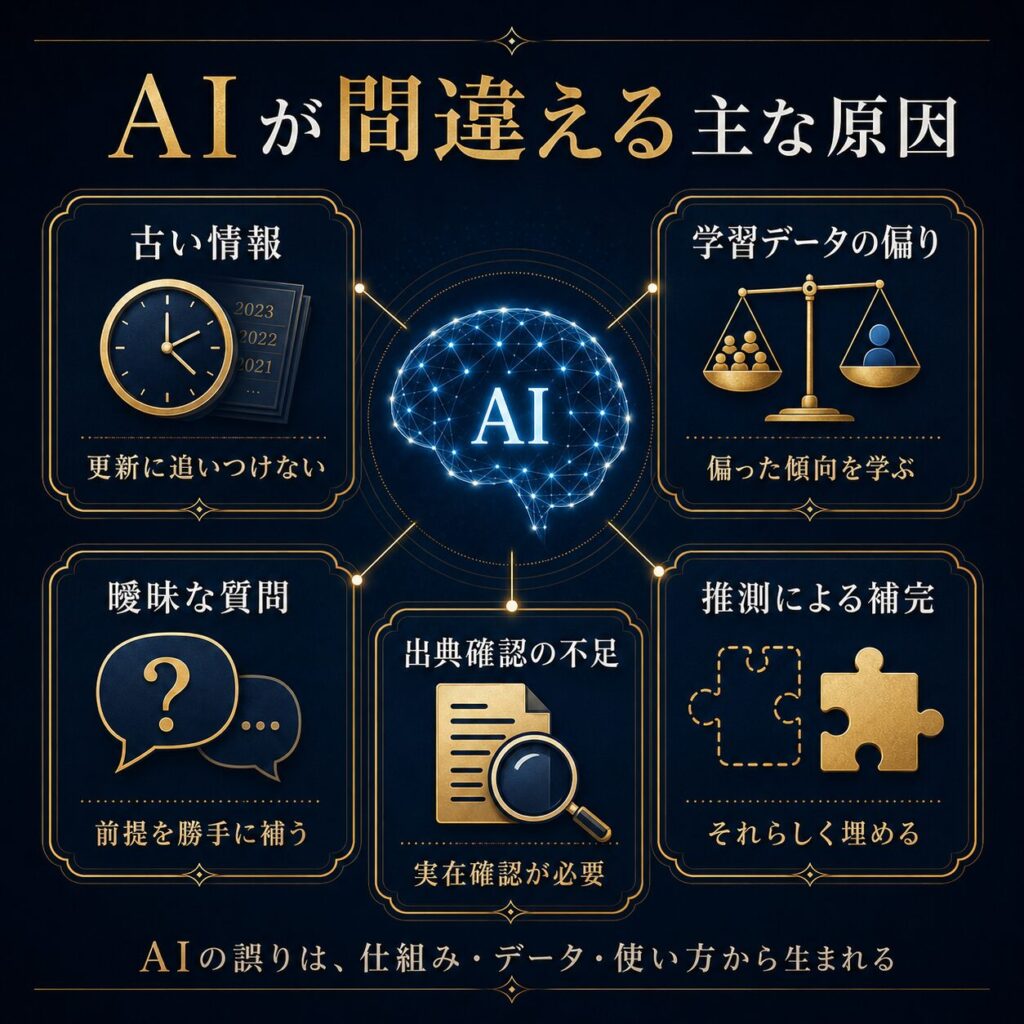
AIは、最新情報に弱いことがあります。
理由は、AIがいつ、どの情報までを学習しているかによって、答えられる内容が変わるからです。
また、Web検索機能などを使える場合でも、最新情報の読み取りや解釈を間違えることがあります。
特に注意が必要なのは、変化が速い分野です。
- 法律
- 制度
- 税金
- 補助金
- 医療情報
- 薬
- 金融商品
- 投資情報
- AIサービスの仕様
- セキュリティ情報
- 国際情勢
- 統計データ
- 価格
- スケジュール
たとえば、去年は正しかった制度説明が、今年は変わっていることがあります。
- AIサービスの料金や機能も変わる
- サイバーセキュリティの脅威や推奨設定も更新される
- 法律や医療のガイドラインも変わることがある
そのため、AIが出した答えが自然でも、次の問いが必要です。
- いつの情報なのか?
- 今も有効なのか?
- 公式情報で確認できるのか?
- 国や地域が合っているのか?
- 例外や条件がないのか?
Googleの生成AIに関する説明でも、生成AIは人間ではなく、自分で考えたり感情を持ったりするものではなく、パターンを見つけるのが得意なものだと説明されています。
また、生成AIが答えを作り出してしまうことはハルシネーションと呼ばれます。(Googleサポート)
AIは便利な入口です。
ですが、変化が速い情報は、AIだけで完結させない方がよいのです。
第5章 質問が曖昧だと、AIは勝手に補う
AIが間違える理由の一つは、質問が曖昧なままでも答えようとすることです。
たとえば、あなたがAIにこう聞いたとします。
「AIの規制について教えて」
この質問だけでは、かなり曖昧です。
- どの国の規制か?
- いつ時点の話か?
- 個人利用の話か?
- 企業利用の話か?
- 著作権の話か?
- プライバシーの話か?
- 医療AIの話か?
- 生成AI全般の話か?
こうした条件が不足しています。
ですが、AIは質問が曖昧でも、何らかの答えを作ろうとします。
その結果、AIが勝手に前提を補うことがあります。
質問が曖昧
↓
AIが前提を推測する
↓
国や分野を勝手に補う
↓
一般論として答える
↓
知りたかった内容とずれる
これは、AIが悪いというより、質問と出力の関係の問題です。
AIは、足りない情報を補って自然な答えを作りますが、あなたの意図と一致するとは限りません。
そのため、AIに質問するときは、できるだけ条件を入れるとよいです。
- どの国の話か?
- いつ時点の話か?
- 誰向けの説明か?
- どの分野の話か?
- どの深さで説明してほしいか?
- 事実と解釈を分けてほしいか?
- 出典を確認してほしいか?
AIの答えがずれるとき、AIだけでなく、質問が曖昧だった可能性もあります。
AIリテラシーとは、AIの出力だけでなく、自分の問いも確認する力なのです。
第6章 AIは「わからない」と言うのが苦手なことがある
人間でも、試験でわからない問題が出ると、つい推測で答えてしまうことがあります。
AIにも似た問題があります。
AIは、質問されると答えを作ろうとします。
不確かなときに「わかりません」と言うより、もっともらしい答えを出してしまうことがあります。
OpenAIの研究は、言語モデルがハルシネーションを起こす理由として、標準的な訓練や評価の手続きが、不確実性を認めるよりも推測して答えることを報酬しやすいと説明しています。(OpenAI)
これは重要です。
AIが自信満々に見えるからといって、本当に確信があるとは限りません。
AIの文章には、次のような表現が出ることがあります。
- 明らかに
- 一般的に
- 確実に
- 代表的な例として
- 広く知られている
- 研究によると
- 専門家は指摘している
こうした表現があっても、事実確認は必要です。
自信のある文章
↓
正しいとは限らない
↓
根拠を確認する
↓
不確かな場合は保留する
↓
人間が判断する
AIを使うときは、「自信がありそうな文体」に引っ張られすぎないことが大切です。
自信のある言い方と、根拠の強さは別なのです。
第7章 学習データの偏りや限界
AIは、学習したデータの影響を受けます。
そのため、学習データに偏りや誤りがあれば、AIの出力にも影響することがあります。
たとえば、次のような問題です。
- 特定の国や地域の情報に偏る
- 古い価値観が反映される
- 少数派の情報が不足する
- 誤った情報が混ざる
- 差別的な表現が含まれる
- 特定の文体や立場に寄る
- ネット上に多い説明が強く出る
AIは、学習データを人間のように吟味しているわけではありません。
データに含まれる傾向を学びます。
そのため、多く出てくる説明や表現が、より自然に出やすくなることがあります。
NISTの生成AIプロファイルでは、生成AIのリスクとして、バイアス、情報の完全性、プライバシー、知的財産、セキュリティなどが整理されています。
AIの出力を見るときは、出力そのものだけでなく、背景にあるデータの偏りや限界も考える必要があります。(NIST)
ここで大切なのは、AIの出力を「中立」と決めつけないことです。
AIは、偏りのない神の視点を持っているわけではありません。
学習したデータ、設計、調整、使い方の影響を受けています。
だからこそ、センシティブなテーマでは特に注意が必要です。
- 戦争
- 宗教
- 民族
- ジェンダー
- 医療
- 法律
- 犯罪
- 政治
- 歴史
- 社会問題
こうしたテーマでは、AIの答えをそのまま使うのではなく、立場、出典、事実、解釈を分けることが大切です。
第8章 AIの間違いが危険になる場面
AIの間違いは、すべてが同じ重さではありません。
雑談やアイデア出しで少しずれても、大きな問題にならないことがあります。
一方で、間違いが重大な影響につながる場面もあります。
特に注意したいのは、次の分野です。
- 医療
- 法律
- 金融
- 投資
- 税金
- 雇用
- 教育評価
- 安全保障
- サイバーセキュリティ
- 災害情報
- 人の名誉や信用に関わる情報
たとえば、医療情報で誤った説明を信じると、受診の遅れにつながるかもしれません。
法律や税金の説明を誤解すると、手続きや判断を間違えるかもしれません。
金融や投資の情報を鵜呑みにすると、損失につながることがあります。
人に関する誤情報を発信すれば、名誉や信用を傷つける可能性があります。
つまり、AIの答えは、使う場面によって危険度が変わります。
- 低リスク
- アイデア出し
- 下書き
- 文章の言い換え
- 学習の入口
- 旅行プランのたたき台
- 高リスク
- 医療判断
- 法律判断
- 投資判断
- 人事評価
- セキュリティ対応
- 公開情報としての発信
AIを使うときは、次の問いが重要です。
この答えが間違っていたら、誰が困るのか?
困る人が多いほど、確認のレベルを上げる必要があります。
第9章 AIの間違いを見る5つの問い

AIの答えに違和感があるとき、または重要な内容に使うときは、次の5つの問いを持つと整理しやすくなります。
「これは事実なのか、推測なのか、一般論なのか?」
「数字・日付・固有名詞は確認できるのか?」
「出典は実在し、内容と一致しているのか?」
「質問が曖昧で、AIが勝手に前提を補っていないか?」
「間違っていた場合、誰にどんな影響が出るのか?」
たとえば、AIに「この制度について説明して」と聞いた場合。
- これは事実なのか、推測なのか、一般論なのか?
- 法律の条文なのか
- 一般的な説明なのか
- AIの推測なのか
- 過去の制度をもとにした説明なのか
- 数字・日付・固有名詞は確認できるのか?
- 施行日は正しいか
- 金額は正しいか
- 制度名は正しいか
- 担当機関は正しいか
- 出典は実在し、内容と一致しているのか?
- 公式資料はあるか
- 引用部分は本当に書かれているか
- AIの説明と出典内容が一致しているか
- 資料の日付は古くないか
- 質問が曖昧で、AIが勝手に前提を補っていないか?
- 国や地域は合っているか
- 個人向けか企業向けか
- 最新情報なのか
- 例外や条件はあるか
- 間違っていた場合、誰にどんな影響が出るのか?
- 自分だけか
- 仕事相手に影響するか
- 顧客に影響するか
- 読者に影響するか
- 法的・金銭的な影響があるか
この5つの問いを持つだけで、AIの答えとの距離感が変わります。
AIの答えを信じるか疑うかではなく、どこを確認すべきかを見ることが大切なのです。
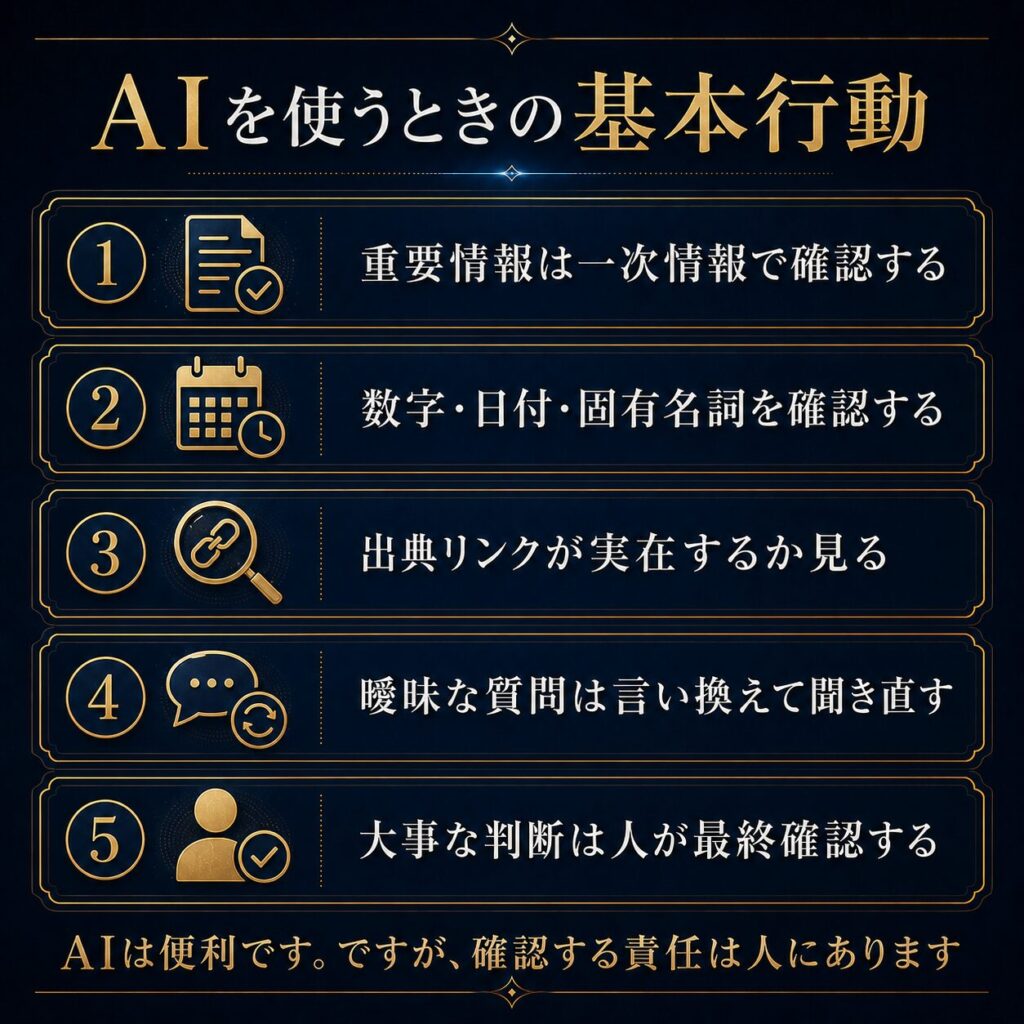
第10章 AIの間違いを減らす使い方
AIの間違いをゼロにすることは難しいです。
ですが、使い方によって、リスクを下げることはできます。
まず、質問を具体的にします。
- 目的を伝える
- 読者や対象者を伝える
- 国や地域を指定する
- 時点を指定する
- 事実と解釈を分けてもらう
- 不確かな点は不確かと言ってもらう
- 出典が必要な部分を明示する
- 重要な数字は確認対象として扱う
たとえば、悪い聞き方はこうです。
「AI規制について教えて」
これだと曖昧です。
よりよい聞き方はこうです。
「2026年時点の日本における生成AI利用に関する企業向けの主な注意点を、事実と解釈を分けて整理してください。不確かな点は不確かと明記してください。」
このように聞くと、AIが勝手に前提を補いすぎるリスクを少し下げられます。
次に、出力後の確認も大切です。
AIに下書きを作らせる
↓
重要な主張を抜き出す
↓
数字・固有名詞・日付を確認する
↓
公式情報や一次情報を見る
↓
必要なら専門家に確認する
↓
人間が判断して使う
AIの間違いを減らす最も大切な方法は、AIに完璧を求めることではありません。
AIを下書きや整理役として使い、確認を人間が担うことです。
まとめ AIは間違える。だから、確認して使う
AIは便利です。
- 文章を作る
- 要約する
- 説明する
- アイデアを出す
- 表を整理する
- コードを書く
- 学習を助ける
こうした作業で、大きな力を発揮します。
ですが、AIは間違えます。
- 存在しない情報を出す
- 古い情報を混ぜる
- 数字を間違える
- 人名や日付を取り違える
- 出典が不明な説明をする
- 質問の前提を勝手に補う
- 一般論を事実のように見せる
- 自信のある文体で誤る
AIの間違いが難しいのは、文章が自然だからです。
自然な文章は、正しく見えます。
ですが、自然さは正確さを保証しません。
AIが間違える理由には、さまざまなものがあります。
- 学習データの偏り
- 古い情報
- 質問の曖昧さ
- 出典確認の不足
- 推測による補完
- 不確かさを認めにくい出力
- 自然な文章を作る仕組み
だからこそ、AIを使うときは、次の流れが大切です。
AIに聞く
↓
答えを受け取る
↓
事実・推測・一般論を分ける
↓
数字・出典・固有名詞を確認する
↓
間違った場合の影響を考える
↓
人間が判断して使う
AIを過信しない。
AIを拒絶もしない。
AIは間違えるものとして、確認しながら使う。
これが、AIリテラシーの基本です。
次回は、「AIの答えはどう確認すればよいのか」を扱います。
「AIが出した情報を、どこで確認すればよいのか?」
「一次情報とは何か?」
「公式情報、論文、報道はどう使い分ければよいのか?」
「医療・法律・金融など、高リスク領域では何に注意すべきなのか?」
こうした問いを、実践的な確認方法として整理していきます。
次回の記事はこちらです。
【第4回】AIの答えはどう確認すればよいのか|一次情報・出典・事実確認の基本をわかりやすく解説

シリーズ全体はこちらから確認できます。
【まとめ】AIリテラシーとは何か|生成AIを安全に使うための基礎講座まとめ
ここまでお読みいただきありがとうございました。
Veritas Labでは、国際情勢・歴史・科学・心理学・サイバーセキュリティを横断しながら、複雑な世界の構造を読み解いています。
このブログの考え方や、初めての方におすすめの記事は「Veritas Labの歩き方」にまとめています。
もしご興味あればお読みいただけると嬉しいです。

あわせて読みたい本
この記事では、AIがなぜ間違えるのかを、ハルシネーション、学習データ、質問の曖昧さ、出典確認の視点から整理しました。
さらに深く理解したい場合は、生成AIの仕組み、情報リテラシー、認知バイアス、AI倫理を扱った入門書を読むと、AIの出力と人間の判断の関係が見えやすくなります。
ただし、AIの技術や制度は変化が速いため、実務的な確認では、NIST、IPA、OpenAI、Google、IBMなどの公式情報を優先するのがおすすめです。
※一部リンクにはアフィリエイトを利用しています。
あなたの負担が増えることはありません。
いただいた収益は、ブログ運営や書籍購入などの学習費に充てています。
- 栗原 聡『AIの倫理 人間との信頼関係を創れるか』
- 小木曽 健『13歳からの「ネットのルール」 誰も傷つけないためのスマホリテラシーを身につける本』
- 情報文化研究所, 米田 紘康, 竹村 祐亮, 石井 慶子, 高橋 昌一郎 『情報を正しく選択するための認知バイアス事典 行動経済学・統計学・情報学 編』
参考情報
- Google Cloud「What are AI hallucinations?」
- AIハルシネーションを、AIモデルが生成する誤った、または誤解を招く結果として説明しています。
- 不十分な学習データ、モデルの誤った仮定、データのバイアスなどの原因を確認できます。
https://cloud.google.com/discover/what-are-ai-hallucinations
- IBM「What Are AI Hallucinations?」
- AIハルシネーションの原因として、過学習、学習データの偏りや不正確さ、モデルの複雑さなどを確認できます。
https://www.ibm.com/think/topics/ai-hallucinations
- AIハルシネーションの原因として、過学習、学習データの偏りや不正確さ、モデルの複雑さなどを確認できます。
- OpenAI「Why language models hallucinate」
- 言語モデルがハルシネーションを起こす理由として、不確実性を認めるよりも推測して答えることが評価されやすい訓練・評価構造を説明しています。
https://openai.com/index/why-language-models-hallucinate/
- 言語モデルがハルシネーションを起こす理由として、不確実性を認めるよりも推測して答えることが評価されやすい訓練・評価構造を説明しています。
- Google Workspace Learning Center「Learn about generative AI」
- 生成AIは人間ではなく、自分で考えたり感情を持ったりするものではなく、パターンを見つけるのが得意なものだと説明しています。
https://support.google.com/a/users/answer/13954172
- 生成AIは人間ではなく、自分で考えたり感情を持ったりするものではなく、パターンを見つけるのが得意なものだと説明しています。
- NIST「Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile」
- 生成AIのリスクとして、情報の完全性、偽情報、バイアス、プライバシー、知的財産、セキュリティなどを整理しています。
https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
- 生成AIのリスクとして、情報の完全性、偽情報、バイアス、プライバシー、知的財産、セキュリティなどを整理しています。

