この記事は、「AIリテラシー基礎講座」第2回です。
今回は、AIがなぜ自然な文章を出せるのかを、仕組みの面から整理します。
シリーズ全体はこちら:【まとめ】AIリテラシーとは何か|生成AIを安全に使うための基礎講座まとめ

「突然ですが、AIに質問したとき、こんなふうに感じたことはありませんか?」
- 人間みたいに答えている
- ちゃんと意味を理解しているように見える
- 文章が自然すぎて驚く
- 難しい話もわかりやすく説明してくれる
- 自分の質問の意図を読んでいるように見える
- それっぽい答えだけれど、本当に正しいのか少し不安になる
生成AIは、とても自然な文章を返します。
- 質問に答える
- 文章を要約する
- 説明をやさしくする
- メール文を作る
- アイデアを出す
- 会話の流れに合わせて返す
こうしたことができます。
そのため、まるでAIが人間のように理解しているように感じることがあります。
ですが、ここで大切なのは、「自然な文章」と「正しい理解」は同じではないということです。
AIは、人間と同じように世界を経験しているわけではありません。
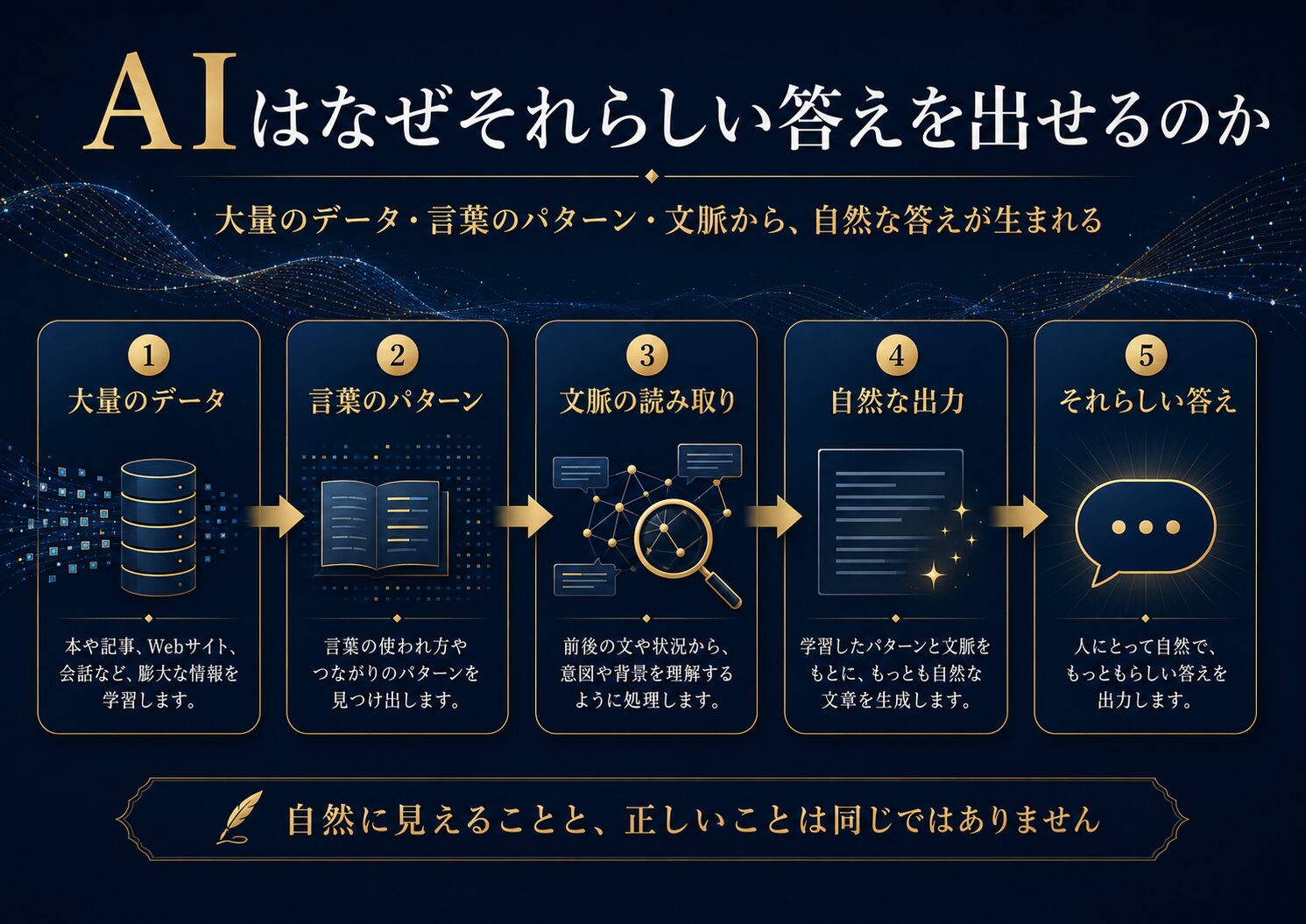
では、なぜそれでも、AIはそれらしい答えを出せるのでしょうか?
大きな理由は、大量のデータから言葉のパターンを学び、文脈に合いそうな出力を作っているからです。
IBMは、大規模言語モデルについて、大量のテキストデータを処理することで人間の言語を理解・生成できるAIシステムであり、Transformerというニューラルネットワーク構造を使って言葉の並びやパターンを扱うと説明しています。(IBM)
今回は、「AIはなぜそれらしい答えを出せるのか」を見ていきます。
「AIは本当に理解しているのか?」
「学習データとは何か?」
「パターンを学ぶとはどういうことか?」
「文脈に合う答えは、どう作られるのか?」
「なぜ、それらしいのに間違うことがあるのか?」
こうした問いを、AIリテラシーの土台として整理していきます。
この記事の立場
この記事では、AIが自然な答えを出せる理由を、学習データ、パターン、文脈、予測の仕組みから整理します。
ただし、AIモデルを作るための専門的な実装手順や、悪用につながる使い方には踏み込みません。
目的は、あなたがAIの答えを過信せず、「なぜ自然に見えるのか」「なぜ間違うことがあるのか」を理解して、確認しながら使えるようにすることです。
第1章 AIは「答えを知っている」のか?
AIに質問すると、すぐに答えが返ってきます。
そのため、AIが頭の中に正解を持っていて、それを取り出しているように見えるかもしれません。
ですが、生成AIの答え方は、人間が辞書や百科事典から正解を取り出すのとは少し違います。
生成AIは、入力された言葉の流れをもとに、次に続くと自然に見える言葉や文章を作っていると考えるとわかりやすいです。
AIは質問を受け取る
↓
言葉の並びや文脈を見る
↓
過去に学んだパターンと照らし合わせる
↓
続きとして自然な出力を作る
↓
文章として返す
もちろん、これはかなり簡略化した説明です。
実際のAIは、もっと複雑な計算をしています。
ですが、AIリテラシーとして最初に押さえるなら、ここが重要です。
- AIは自然な答えを作れる。
- ただし、その答えが必ず正しいとは限らない。
ここを分けて考える必要があります。
たとえば、AIに「原爆と水爆の違いを説明して」と聞くと、自然な説明を返してくれるかもしれません。
ですが、その説明の数字、歴史、制度、出典が正しいかは、別に確認する必要があります。
自然に見えることと、事実として正しいことは違うのです。
第2章 学習データとは何か?
AIがそれらしい答えを出せる背景には、学習データがあります。
学習データとは、AIがパターンを学ぶために使うデータのことです。
たとえば、言語モデルであれば、学習には大量の文章データが使われます。
- 本
- Webページ
- 記事
- 説明文
- 会話文
- コード
- 翻訳文
- 文章の構造
- 言葉の使われ方
こうしたデータから、AIは言葉の関係やパターンを学びます。
ただし、ここで注意したいのは、AIが学習データを人間のように読んで理解しているわけではないことです。
AIは、文章に含まれる言葉のつながり、文脈、使われ方の傾向を数学的に扱います。
たとえば、人間もたくさん文章を読めば、次のような感覚を持ちます。
- この言葉の後には、この表現が続きやすい
- この話題では、この説明がよく出てくる
- この文体なら、この言い方が自然に見える
- この質問には、この順番で説明するとわかりやすい
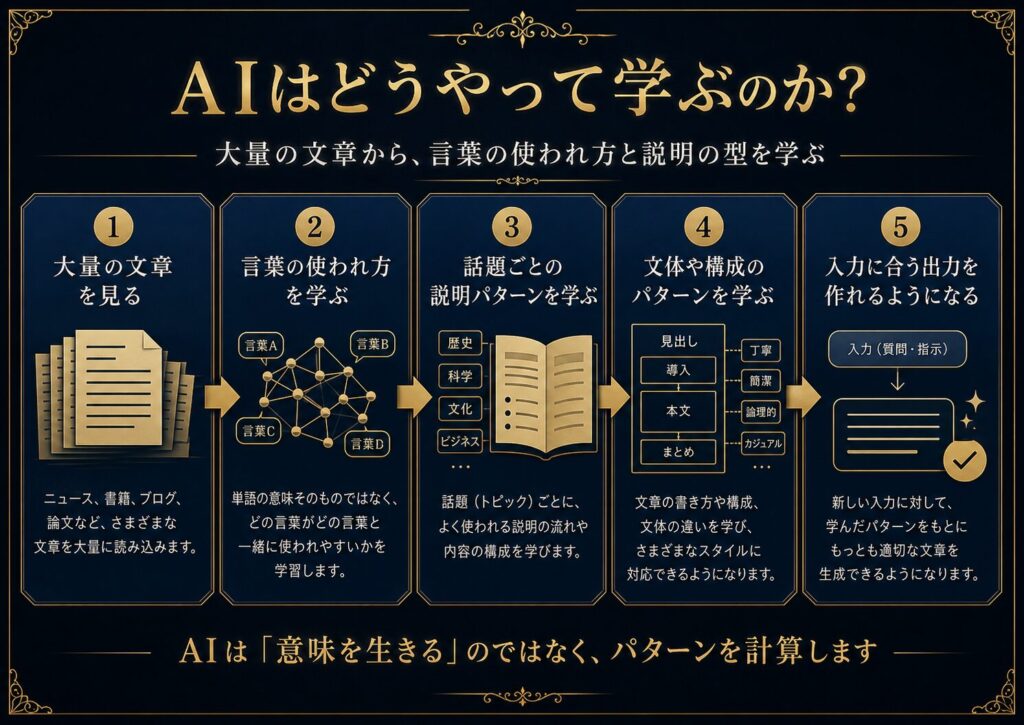
AIも、大量のデータからこうした傾向を学びます。
大量の文章を見る
↓
言葉の使われ方を学ぶ
↓
話題ごとの説明パターンを学ぶ
↓
文体や構成のパターンを学ぶ
↓
入力に合う出力を作れるようになる
ここで見えてくるのは、AIの強さと弱さです。
AIは、大量のデータからパターンを学ぶのが得意です。
一方で、学習データに偏りや誤りがあれば、その影響を受ける可能性があります。
NISTの生成AIプロファイルは、生成AIに関わるリスクとして、データや出力に関わる情報の完全性、バイアス、プライバシー、知的財産、偽情報などを整理しています。
つまり、AIの出力を見るときには、学習や出力の背景にあるデータの問題も意識する必要があります。(NIST)
AIの答えは、何もないところから生まれているわけではありません。
過去のデータとパターンに強く影響されているのです。
第3章 パターンを学ぶとはどういうことか?
AIが学ぶのは、単語の意味だけではありません。
言葉と言葉の関係、文章の流れ、説明の型、文脈のつながりです。
たとえば、次の文章を考えてみます。
「今日は雨が降っているので、傘を……」
多くの人は、次に「持っていく」「差す」「持った方がいい」などが続きそうだと予想できます。
なぜでしょうか?
それは、過去の経験や言葉の使われ方から、「雨」と「傘」が関係していることを知っているからです。
AIも、こうした関係を大量のデータから学びます。
もちろん、人間の生活経験とは違います。
AIは雨に濡れた経験があるわけではありません。
ですが、文章の中で「雨」「傘」「濡れる」「天気」「外出」がどのように一緒に使われるかを学ぶことで、自然な続きを作れるようになります。
- 言葉Aとよく一緒に使われる言葉
- 説明でよく出る順番
- 質問と回答の組み合わせ
- 文章の文体
- 話題ごとの典型的な構成
- 文脈に合う表現
この「パターンを学ぶ力」が、AIの自然さを支えています。
AIは、問いに対して、過去に見た多くの文章パターンをもとに、もっとも自然に見える説明を組み立てます。
そのため、AIの答えはなめらかです。
ですが、ここに注意点があります。
自然に見える答えは、パターンとして自然な答えであって、必ずしも事実として正しい答えではありません。
ここを理解することが、AIリテラシーの重要な土台です。
第4章 トークンとは何か?
AIが文章を扱うとき、文章をそのまま一つのかたまりとして見ているわけではありません。
多くの場合、文章はトークンという小さな単位に分けられます。
トークンは、単語に近い場合もあります。
単語の一部である場合もあります。
日本語では、ひらがな、漢字、単語の一部、記号などが組み合わさって扱われることがあります。
たとえば、AIは文章をざっくり次のように分けて扱います。
文章
↓
小さな単位に分ける
↓
それぞれの単位を数字として扱う
↓
数字の関係を計算する
↓
次に続く出力を作る
なぜ数字にするのでしょうか?
コンピューターは、言葉そのものを人間のように感じ取るわけではありません。
そのため、言葉を計算できる形に変える必要があります。
これにより、AIは言葉同士の関係を計算できます。
- この言葉はどの言葉と関係が強いか
- この文脈では何が重要か
- 次にどんな表現が続きやすいか
- 質問のどの部分に注目すべきか
トークンの考え方を知ると、AIの見え方が少し変わります。
AIは文章を「意味のある文章」として読むだけでなく、計算できる単位に分けて処理しています。
だからこそ、
- 長すぎる文章では文脈を見落とすことがある
- 曖昧な指示では、意図と違う答えを出すことがある
- 細かなニュアンスがずれることもある
AIがそれらしく答えられる理由は、言葉を細かく分け、関係を計算しているからなのです。
第5章 文脈を見るとはどういうことか?
AIの答えが自然に見える理由の一つは、文脈を見ているからです。
文脈とは、前後の流れです。
たとえば、同じ「はし」という言葉でも、文脈によって意味が変わります。
- はし(橋)を渡る
- はし(箸)でご飯を食べる
人間は、前後の文章から意味を判断します。
AIも、入力された文章の前後関係をもとに、どの意味が自然かを判断しようとします。
ここで重要になるのが、Transformerという仕組みです。
IBMは、Transformerを、言葉のような連続したデータを処理するニューラルネットワーク構造であり、大規模言語モデルと特に関係が深いものとして説明しています。
Transformerは、文章の中で離れた要素同士の関係も扱いやすい仕組みとして使われています。(IBM)
難しく聞こえるかもしれません。
ここでは、こう理解すれば十分です。
- AIは単語を一つずつ見るだけではない
- 前後の文脈を見る
- どの言葉が重要かを見る
- 離れた言葉同士の関係も見る
- そのうえで自然な出力を作る
たとえば、あなたがAIにこう聞いたとします。
「初心者向けに、AIリテラシーをやさしく説明してください」
このときAIは、次の情報を見ます。
- 初心者向け
- AIリテラシー
- やさしく
- 説明
- してください
そして、「専門用語を減らす」「定義から入る」「例を使う」「丁寧な文体にする」など、文脈に合いそうな出力を作ります。
文脈を見る力があるから、AIは会話に合わせて答えられるのです。
第6章 注意機構とは何か?
AIの仕組みを説明するときに、注意機構という言葉が出てくることがあります。
英語では Attention と呼ばれます。
難しく聞こえますが、AIリテラシーとしては、次のように考えるとわかりやすいです。
文章の中で、どの部分に注目するかを決める仕組みです。
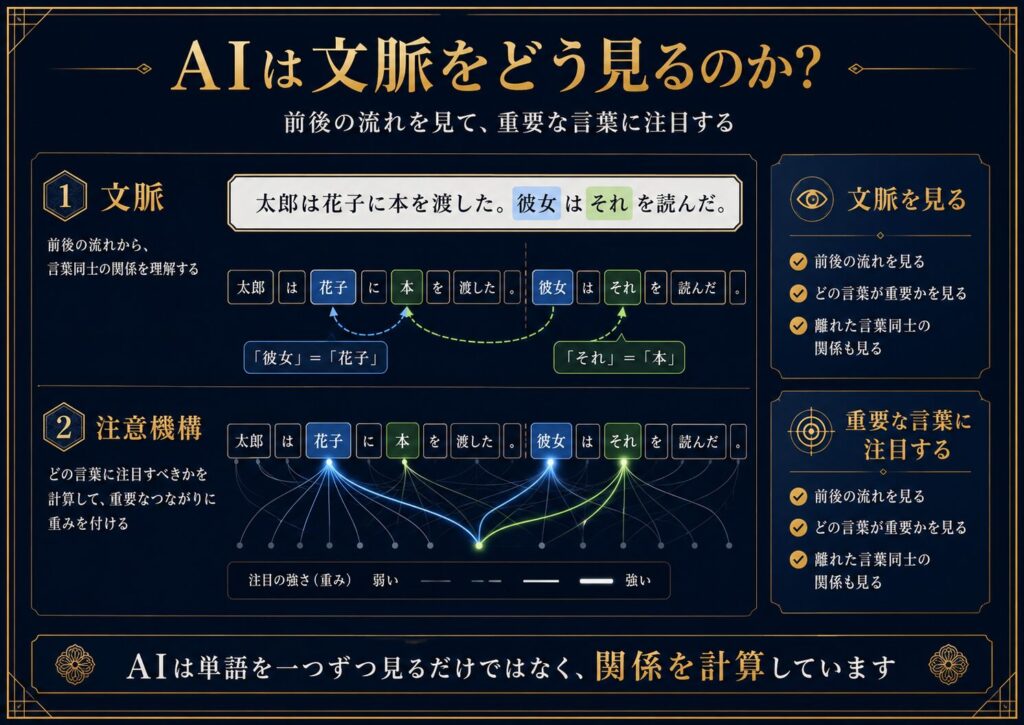
たとえば、次の文を見てみましょう。
「太郎は花子に本を渡した。彼女はそれを読んだ。」
このとき、「彼女」は花子を指していると考えるのが自然です。
「それ」は本を指していると考えられます。
人間は、文脈から関係を読み取ります。
AIも、文章の中のどの言葉がどの言葉と関係しているのかを計算します。
- どの言葉が重要か?
- どの言葉とどの言葉が関係しているか?
- 質問の中心はどこか?
- 前の会話のどこを参照すべきか?
- 出力で何を重視すべきか?
注意機構があることで、AIは文章の流れをよりうまく扱えるようになります。
たとえば、長い質問の中で「要するに何を聞かれているのか」を見つけやすくなります。
前の会話と今の質問をつなげて答えやすくなります。
ただし、これも万能ではありません。
長い文章では重要な部分を見落とすことがあります。
曖昧な質問では、別の意図に解釈することがあります。
会話が長くなると、前提を取り違えることもあります。
つまり、AIは文脈を見る仕組みを持っています。
ですが、人間のようにすべてを深く理解しているわけではないのです。
第7章 AIは本当に理解しているのか?
ここで、多くの人が気になる問いがあります。
AIは本当に理解しているのでしょうか?
答えは、どの意味で「理解」と呼ぶかによって変わります。
AIは、言葉の関係やパターンを使って、自然な答えを作れます。
文章の構造も扱えますし、質問の意図に沿ったような答えも出せます。
その意味では、AIは高度な言語処理をしています。
一方で、人間の理解とは違います。
人間は、経験、身体、感情、記憶、責任、人間関係、社会的文脈を持っています。
AIには、それがありません。
- 人間は経験する
- AIはデータから学ぶ
- 人間は意味を生きる
- AIはパターンを計算する
- 人間は責任を持つ
- AIは責任を持たない
たとえば、人間が「痛み」という言葉を理解するとき、実際の痛みの経験や他者への共感が関わります。
AIは「痛み」という言葉がどのような文脈で使われるかを学べます。
ですが、痛みを感じているわけではありません。
ここが重要です。
AIは、人間のように世界を生きて理解しているわけではありません。
ただし、言葉のパターンを扱う力は非常に高い。
だからこそ、理解しているように見えるのです。
AIを使うときは、この違いを忘れないことが大切です。
第8章 なぜ「それらしいのに間違う」のか?

AIの答えで最も注意したいのは、それらしいのに間違うことです。
なぜ、そんなことが起きるのでしょうか?
理由は、AIが自然な文章を作る力に優れているからです。
- AIは、文脈に合う説明を作る
- 文章の流れも整える
- 専門用語も使える
- 説得力のある構成も作れる
ですが、出力の自然さは、事実の正しさを保証しません。
文体が自然
↓
説明がわかりやすい
↓
正しそうに見える
↓
でも事実確認は別問題
たとえば、
- AIが存在しない論文名を出すことがある
- 実在しない統計をそれらしく説明することがある
- 実在する制度について、古い情報を混ぜることがある
- 人物名や年号を間違えることもある
NISTの生成AIプロファイルでも、生成AIに関するリスクとして、情報の完全性や偽情報、プライバシー、セキュリティ、知的財産などが整理されています。
自然な生成ができるからこそ、出力の信頼性を確認する必要があります。(NIST技術シリーズ出版物)
ここで必要なのは、AIを完全に疑うことではありません。
AIを使ったうえで、重要なところを確認することです。
AIに説明させる
↓
重要な主張を抜き出す
↓
数字や出典を確認する
↓
公式情報や一次情報を見る
↓
人間が判断して使う
AIの答えは、便利な下書きになります。
ですが、確認なしに事実として扱うのは危険なのです。
第9章 AIの答えを見る5つの問い

AIがそれらしい答えを出したときは、次の5つの問いを持つと整理しやすくなります。
「AIは何を根拠に答えているように見えるのか?」
「その答えは、事実なのか、推測なのか、一般論なのか?」
「数字・引用・出典は確認できるのか?」
「質問が曖昧で、AIが勝手に補っていないか?」
「最終的に、人間が確認して判断しているか?」
たとえば、AIに「最新のAI規制について教えて」と聞いた場合。
- AIは何を根拠に答えているように見えるのか?
- 一般的な知識
- 過去の情報
- 推測
- 似た制度との比較
- 最新情報を確認していない可能性
- その答えは、事実なのか、推測なのか、一般論なのか?
- 制度名は事実か
- 施行日は正しいか
- 国や地域が混ざっていないか
- 解釈と事実が分かれているか
- 数字・引用・出典は確認できるのか?
- 公式資料はあるか
- 法令や政府発表はあるか
- 研究や報道は確認できるか
- 日付は最新か
- 質問が曖昧で、AIが勝手に補っていないか?
- どの国の話か
- どの時点の話か
- 個人利用か企業利用か
- 法律かガイドラインか
- 最終的に、人間が確認して判断しているか?
- 公開してよい内容か
- 読者に誤解を与えないか
- 専門家確認が必要ではないか
- 自分の責任で使えるか
この5つを持つだけで、AIの答えに飲み込まれにくくなります。
AIの自然さに驚くことは悪くありません。
ただし、自然だから正しいとは限らない。
ここを忘れないことが大切です。
第10章 AIを上手に使うための考え方
AIを上手に使うには、AIを「正解を出す機械」と考えすぎないことです。
むしろ、次のように考えると使いやすくなります。
- AIは下書きを作る
- AIは視点を増やす
- AIは構成を整理する
- AIは言い換えを助ける
- AIは比較の入口を作る
- AIは質問を深める
- ただし、最終確認は人間が行う
たとえば、あなたが記事を書くとします。
AIには、次のような使い方ができます。
- 読者が疑問に思いそうな点を出してもらう
- 章構成の案を作る
- 難しい説明をやさしく言い換える
- 反論や注意点を洗い出す
- 誤解されやすい表現を指摘してもらう
- 参考情報の候補を整理する
一方で、次のことは人間が行います。
- 事実確認
- 出典確認
- 読者への配慮
- 最終的な表現
- 公開するかどうかの判断
- 責任を持つこと
AIは、思考を助ける道具です。
ですが、思考そのものを外注しきる道具ではありません。
AIがそれらしい答えを出せるからこそ、私たちはより丁寧に確認する必要があります。
まとめ AIの自然さは、学習データとパターンから生まれる
AIは、なぜそれらしい答えを出せるのでしょうか?
理由は、大量のデータから言葉のパターンを学び、文脈に合いそうな出力を作っているからです。
- AIは、文章を細かい単位に分ける
- 言葉同士の関係を計算する
- 前後の文脈を見る
- どの部分に注目するかを判断する
- そして、自然に見える文章を生成する
大量のデータ
↓
言葉のパターン
↓
文脈の読み取り
↓
自然な出力
↓
それらしい答え
ただし、自然に見えることと、正しいことは違います。
- AIは、世界を人間のように経験しているわけではない
- 痛みを感じているわけではない
- 社会的責任を持って判断しているわけでもない
- AIは非常に強力な言語処理を行う
ですが、人間の理解と同じではありません。
だからこそ、AIを使うときには、次の姿勢が必要です。
AIに聞く
↓
自然な答えを得る
↓
重要な主張を抜き出す
↓
事実・数字・出典を確認する
↓
人間が判断する
AIを過信せずに仕組みを知ったうえで使う。
これが、AIリテラシーの基本です。
次回は、「AIはなぜ間違えるのか」を扱います。
「ハルシネーションとは何か?」
「なぜ存在しない情報をそれらしく答えるのか?」
「なぜ古い情報や誤った情報が混ざるのか?」
「AIの間違いに、私たちはどう気づけばよいのか?」
こうした問いを、AIの限界と確認の視点から見ていきます。
次回の記事はこちらです。
【第3回】AIはなぜ間違えるのか|ハルシネーションの仕組みと確認方法をわかりやすく解説

シリーズ全体はこちらから確認できます。
【まとめ】AIリテラシーとは何か|生成AIを安全に使うための基礎講座まとめ
ここまでお読みいただきありがとうございました。
Veritas Labでは、国際情勢・歴史・科学・心理学・サイバーセキュリティを横断しながら、複雑な世界の構造を読み解いています。
このブログの考え方や、初めての方におすすめの記事は「Veritas Labの歩き方」にまとめています。
もしご興味あればお読みいただけると嬉しいです。

あわせて読みたい本
この記事では、AIがそれらしい答えを出せる理由を、学習データ、パターン、文脈から整理しました。
さらに深く理解したい場合は、大規模言語モデル、機械学習、認知科学、情報リテラシーを扱った入門書を読むと、AIの自然さと限界がより見えやすくなります。
ただし、AI技術は変化が速いため、実務的な確認では、NIST、OECD、IPA、各AIサービスの公式情報を優先するのがおすすめです。
※一部リンクにはアフィリエイトを利用しています。
あなたの負担が増えることはありません。
いただいた収益は、ブログ運営や書籍購入などの学習費に充てています。
- 栗原 聡『AIの倫理 人間との信頼関係を創れるか』
- 小木曽 健『13歳からの「ネットのルール」 誰も傷つけないためのスマホリテラシーを身につける本』
- 情報文化研究所, 米田 紘康, 竹村 祐亮, 石井 慶子, 高橋 昌一郎 『情報を正しく選択するための認知バイアス事典 行動経済学・統計学・情報学 編』
参考情報
- IBM「What Are Large Language Models?」
- 大規模言語モデルが大量のテキストデータを処理し、人間の言語を理解・生成するAIシステムであること、Transformer構造と関係することを確認できます。
https://www.ibm.com/think/topics/large-language-models
- 大規模言語モデルが大量のテキストデータを処理し、人間の言語を理解・生成するAIシステムであること、Transformer構造と関係することを確認できます。
- IBM「What is a Transformer Model?」
- Transformerが、言葉のような連続したデータを処理するニューラルネットワーク構造であり、大規模言語モデルと深く関係することを確認できます。
https://www.ibm.com/think/topics/transformer-model
- Transformerが、言葉のような連続したデータを処理するニューラルネットワーク構造であり、大規模言語モデルと深く関係することを確認できます。
- NIST「Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile」
- 生成AIに関わるリスクとして、情報の完全性、偽情報、セキュリティ、プライバシー、知的財産、バイアスなどを整理しています。
https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
- 生成AIに関わるリスクとして、情報の完全性、偽情報、セキュリティ、プライバシー、知的財産、バイアスなどを整理しています。
- NIST「AI Risk Management Framework」
- AIリスクを個人、組織、社会の文脈で管理するための枠組みです。信頼できるAIやリスク管理の考え方を確認できます。
https://www.nist.gov/itl/ai-risk-management-framework
- AIリスクを個人、組織、社会の文脈で管理するための枠組みです。信頼できるAIやリスク管理の考え方を確認できます。

